10.1. Density#
Let \(f\) be a non-negative function on the real number line and suppose
Then \(f\) is a probability density function or just density for short.
This integral is the total area under the curve \(f\). The condition that it has to be 1 allows us to think of the areas under the curve as probabilities.
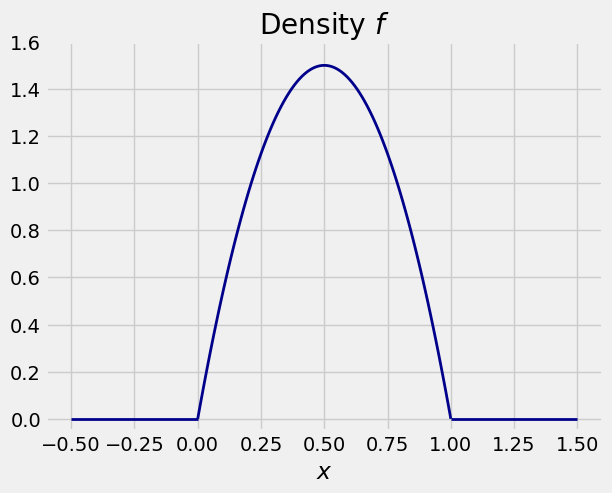
As an example, the function \(f\) defined by
is a density. It is easy to check by calculus that it integrates to 1.
Here is a graph of \(f\). The density puts all the probability on the unit interval.
10.1.1. Density is Not the Same as Probability#
In the example above, \(f(0.5) = 6/4 = 1.5 > 1\). Indeed, there are many values of \(x\) for which \(f(x) > 1\). So the values of \(f\) are clearly not probabilities.
Then what are they? We’ll get to that later in this section. First we will see that we can work with densities just as we did with the normal curve.
10.1.2. Areas are Probabilities#
A random variable \(X\) is said to have density \(f\) if for every pair \(a < b\),
This integral is the area between \(a\) and \(b\) under the density curve. The graph below shows the area corresponding to \(P(0.6 < X \le 0.8)\) for \(X\) with the density in our example.
<>:11: SyntaxWarning: invalid escape sequence '\l'
<>:11: SyntaxWarning: invalid escape sequence '\l'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53839/1859329335.py:11: SyntaxWarning: invalid escape sequence '\l'
plt.title('Gold Area = $P(0.6 < X \leq 0.8)$');
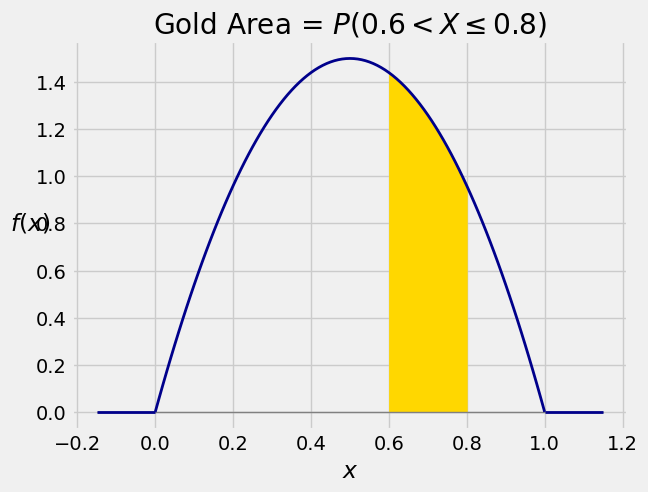
The area is $\( P(0.6 < X \le 0.8) ~ = ~ \int_{0.6}^{0.8} 6x(1-x)dx \)$
We’ll do the integral below.
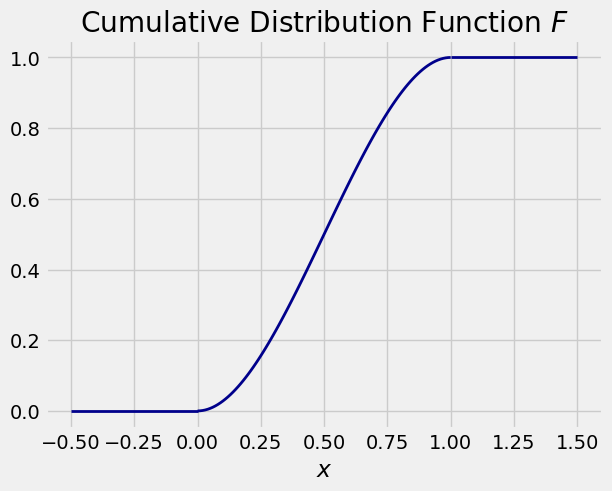
10.1.3. Cumulative Distribution Function (CDF)#
As before, the cdf of \(X\) is the function \(F\) defined by \(F(x) = P(X \le x)\), but now the probability is computed as an integral instead of a sum.
In our example, the density is positive only between 0 and 1, so \(F(x) = 0\) for \(x \le 0\) and \(F(x) = 1\) for \(x \ge 1\). For \(x \in (0, 1)\),
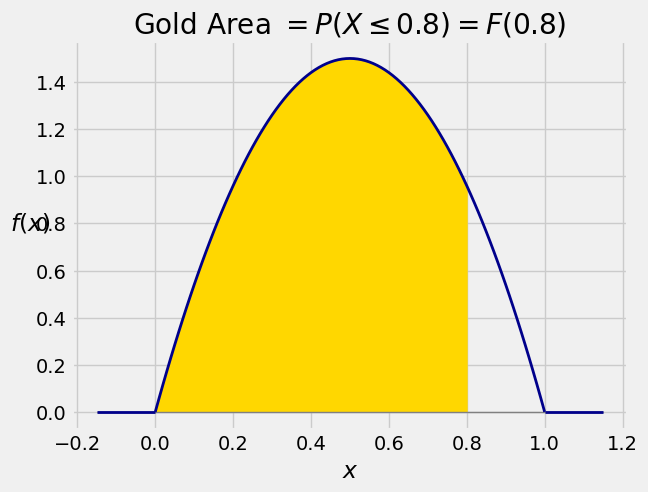
In terms of the graph of the density, \(F(x)\) is all the area to the left of \(x\) under the density curve. The graph below shows the area corresponding to \(F(0.8)\).
<>:11: SyntaxWarning: invalid escape sequence '\l'
<>:11: SyntaxWarning: invalid escape sequence '\l'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53839/3926839598.py:11: SyntaxWarning: invalid escape sequence '\l'
plt.title('Gold Area $= P(X \leq 0.8) = F(0.8)$');
As before, the cdf can be used to find probabilities of intervals. For every pair \(a < b\),
<>:13: SyntaxWarning: invalid escape sequence '\l'
<>:13: SyntaxWarning: invalid escape sequence '\l'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53839/971382585.py:13: SyntaxWarning: invalid escape sequence '\l'
plt.title('Gold Area $= P(0.6 < X \leq 0.8) = F(0.8) - F(0.6)$');
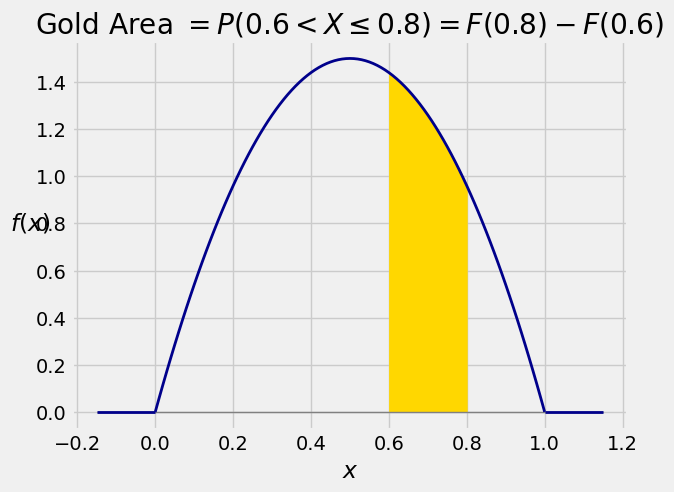
You can get the same answer by integrating the density between 0.6 and 0.8.
By the Fundamental Theorem of Calculus, the density and cdf can be derived from each other:
You can use whichever of the two functions is more convenient in a particular application.
10.1.4. No Probability at Any Single Point#
A wonderful aspect of a random variable that has a density, like the random variable \(X\) above, is that there is no chance of hitting a possible value exactly. That is, for each \(x\), we have \(P(X = x) = 0\). It’s because probabilities are areas under the density curve, and the area of a line is 0.
This is the analog of the fact that each point on the number line has length 0, but intervals still have positive length.
This makes calculations easier, because including or excluding single points in events won’t change the probability. For example,
10.1.5. The Meaning of Density#
While \(P(X = x) = 0\) for each \(x\), the chance that \(X\) is in a tiny interval near \(x\) is positive if \(f(x) > 0\).
The gold strip in the figure below is \(P(X \in (x, x+\Delta x))\) for a very small width \(\Delta x\). The shape of the strip is essentially a rectangle with height \(f(x)\) and with \(\Delta x\). So when \(\Delta x\) is tiny,
<>:10: SyntaxWarning: invalid escape sequence '\D'
<>:12: SyntaxWarning: invalid escape sequence '\i'
<>:10: SyntaxWarning: invalid escape sequence '\D'
<>:12: SyntaxWarning: invalid escape sequence '\i'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53839/71415374.py:10: SyntaxWarning: invalid escape sequence '\D'
plt.xticks([0.8+0.005], ['$\Delta x$'])
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53839/71415374.py:12: SyntaxWarning: invalid escape sequence '\i'
plt.title('Gold Area = $P(X \in (x, x+\Delta x)) \simeq f(x)\Delta x$');
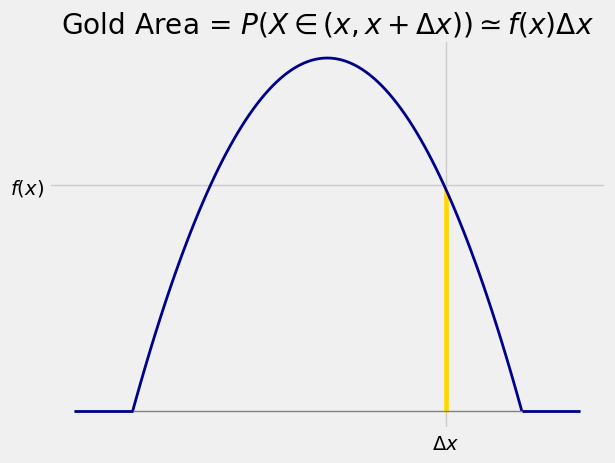
Thus
In other words, \(f\) measures the chance that \(X\) is in a tiny interval near \(x\), relative to the width of the interval.
Let the width \(\Delta x\) get tinier and tinier. In the limit as \(\Delta x\) goes to 0, \(f\) measures probability per unit length. That is why \(f\) is called a probability density function.
Recall from Data 8 that in a discrete histogram, areas represent percents, and the height of the bar over a bin is given by
Probability density is the idealization of this as the amount of data goes becomes infinitely large and the width of each bin becomes infinitesimally small.
10.1.6. Analogous Calculations#
Many calculations involving densities are direct analogs of calculations for discrete random variables.
For example, if \(X\) has density \(f\), then for constants \(a < b\) we have
If instead \(X\) is an integer-valued random variable, then for integers \(a < b\) we have
In the next section we will develop the analogs for calculating expectation and variance.