8.2. Standard Normal Curve#
The normal or Gaussian curves are a family of bell-shaped curves named for the German mathematician and scientist Carl Friedrich Gauss.
Here are few members of the family. You can see that there really is only one bell shape; the differences between the curves are due to where they are centered and how wide the bells are. In other words, the differences are due to the scales on which the variables are being measured.
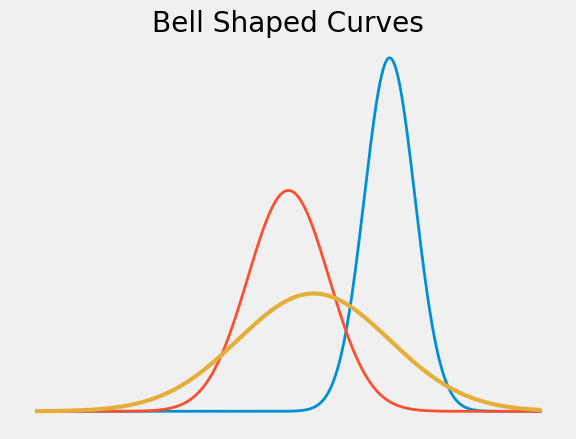
In essence, therefore, there is only one normal curve – all the others can be derived by changing the origin and the units of measurement.
That all-important normal curve is called the standard normal curve. This section is a workout in using the curve. In the next section, we will use these skills and the Central Limit Theorem to approximate probabilities.
8.2.1. The Standard Normal Curve#
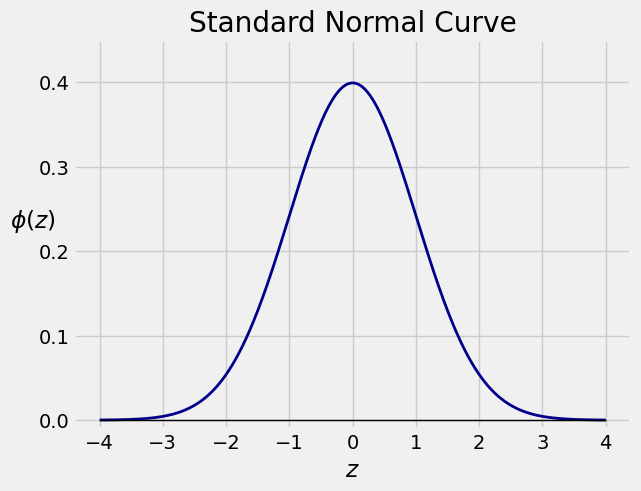
The standard normal curve is defined by
That’s the lower case Greek letter \(\phi\). The figure below shows the graph of \(\phi\).
<>:10: SyntaxWarning: invalid escape sequence '\p'
<>:10: SyntaxWarning: invalid escape sequence '\p'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/503539421.py:10: SyntaxWarning: invalid escape sequence '\p'
plt.ylabel('$\phi(z)$', rotation=0)
Some properties of the curve are clear from the graph or equation. Others need more work to establish. In this course it is enough that you observe what you can and leave the proofs to another class.
The curve is bell-shaped and symmetric about 0.
The points of inflection are at \(z=-1\) and \(z=1\).
Even though the curve is defined over the entire number line, it is pretty close to 0 for \(\vert z \vert > 3\).
The curve can be thought of as an approximation to a probability histogram, because the total area under the curve is 1.
8.2.2. The Standard Normal ‘CDF’#
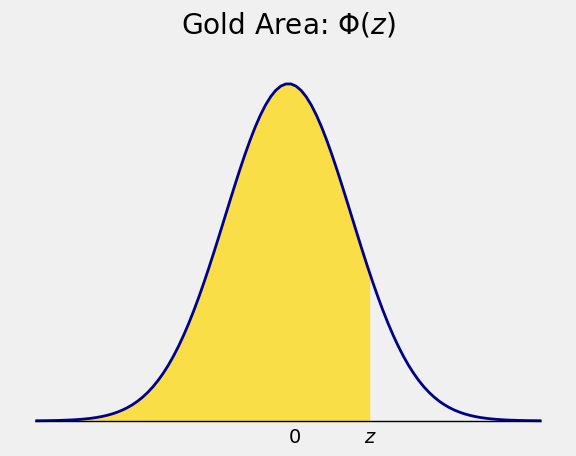
If you think of the standard normal curve as a probability histogram, then it is natural to think of areas under the curve as probabilities. In particular, the function \(\Phi\) defined by
returns all the area under the curve to the left of \(z\), and is called the ‘cdf’. At the moment, think of it as a cdf by analogy with the discrete cumulative distribution functions that you have seen before.
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/2403362488.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(z)$');
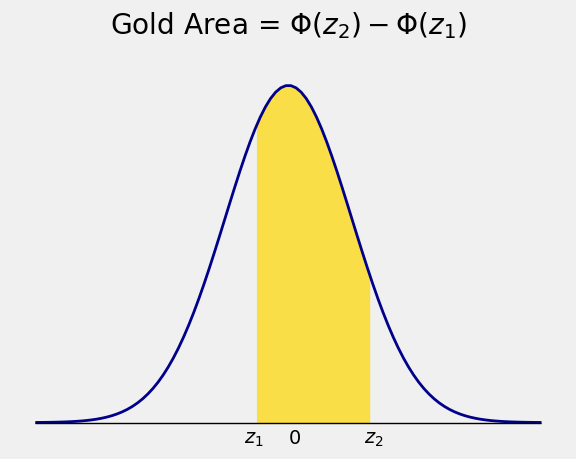
The area under the curve over any interval \((z_1, z_2)\) is then \(\Phi(z_2) - \Phi(z_1)\).
<>:13: SyntaxWarning: invalid escape sequence '\P'
<>:13: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/723216001.py:13: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area = $\Phi(z_2) - \Phi(z_1)$');
8.2.3. Numerical Values of the Areas#
If we had a formula for \(\Phi\), we could plug into that formula to find areas under the standard normal curve. But this is where the curve gets even more interesting: even though we can show that the total area under the curve is 1, there is no closed-form formula for \(\Phi\). The numerical value of the integral has to be evaluated by numerical approximation.
That is why almost all statistics textbooks include a normal distribution table. We can do better because we have Python.
The SciPy function stats.norm.cdf takes in \(z\) and returns \(\Phi(z)\). Thus the value
is found by evaluating the following expression:
stats.norm.cdf(1)
0.84134474606854293
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/1372295587.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(1) \simeq 84\%$');
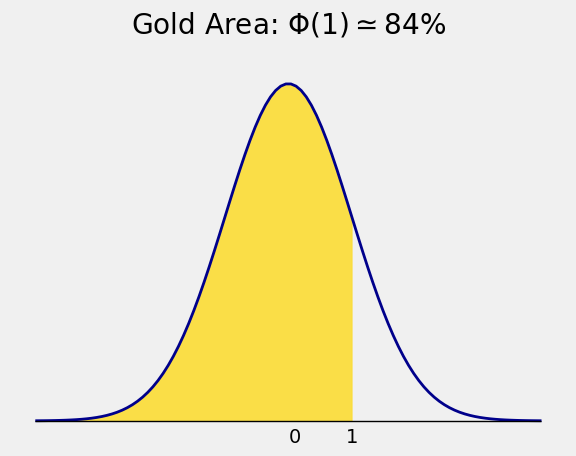
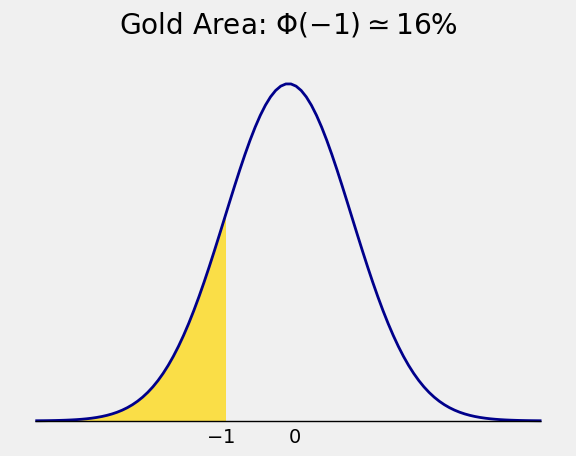
The area of the tail to the right of 1 is therefore about \(16\%\), which by symmetry is the same as \(\Phi(-1)\):
stats.norm.cdf(-1)
0.15865525393145707
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/3892478457.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(-1) \simeq 16\%$');
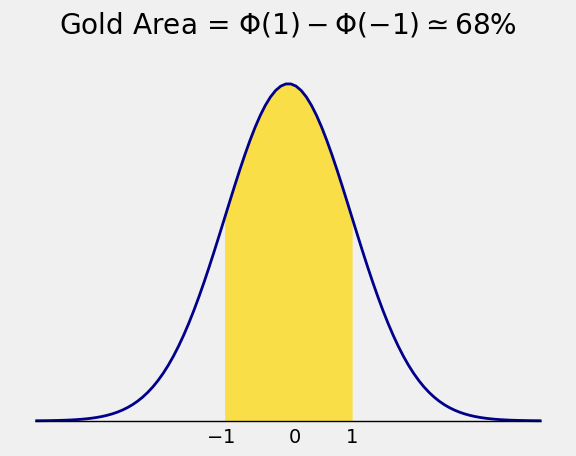
So the area under the standard normal curve between \(-1\) and \(1\) is about 68%:
stats.norm.cdf(1) - stats.norm.cdf(-1)
0.68268949213708585
<>:13: SyntaxWarning: invalid escape sequence '\P'
<>:13: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/828992571.py:13: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area = $\Phi(1) - \Phi(-1) \simeq 68\%$');
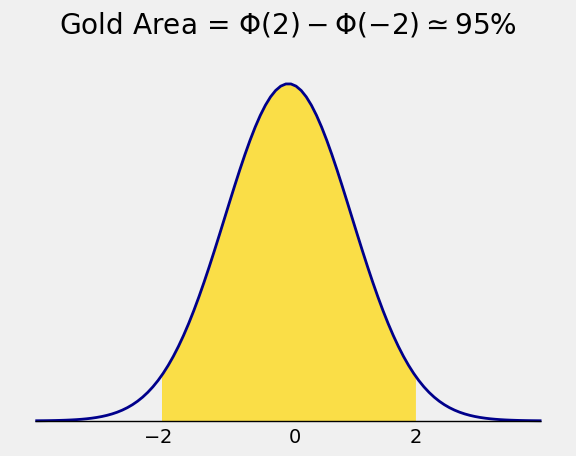
The area between \(-2\) and \(2\) is
stats.norm.cdf(2) - stats.norm.cdf(-2)
0.95449973610364158
<>:13: SyntaxWarning: invalid escape sequence '\P'
<>:13: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/1213313872.py:13: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area = $\Phi(2) - \Phi(-2) \simeq 95\%$');
8.2.4. Percentiles#
The area under the curve to the left of 1 is about 84%
The point \(z = 1\) is therefore called the 84th percentile of the curve. If you think of the curve as a probability histogram, then about 84% of the probability lies below \(z=1\).
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/1372295587.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(1) \simeq 84\%$');
The 90th percentile must be to the right of 1. But how far to the right?
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/3323502589.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(?) \simeq 90\%$');
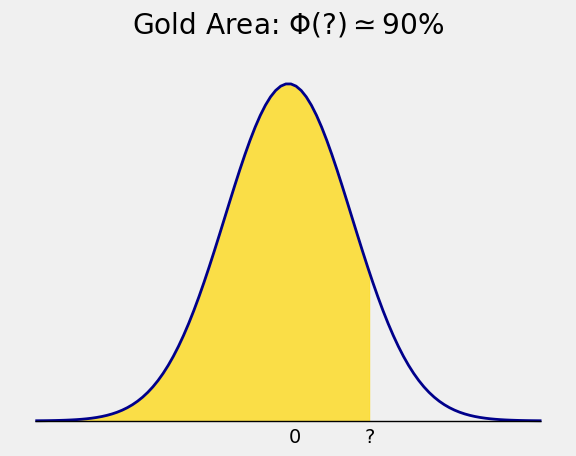
To find it, we need the inverse of \(\Phi\).
The 90th percentile is the point \(z\) such that \(\Phi(z) = 0.9\).
In math notation, the 90th percentile is the point
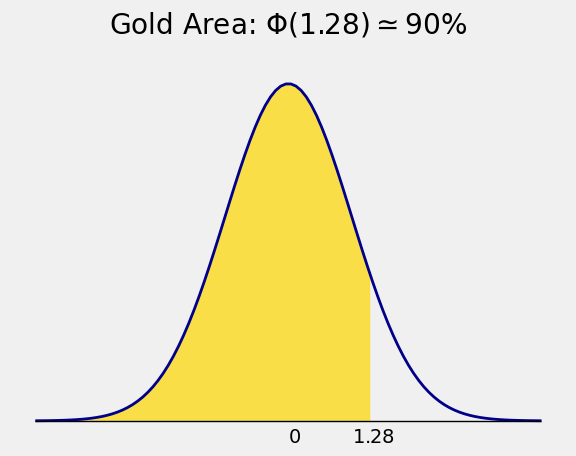
In SciPy, the function \(\Phi^{-1}\) is named ppf for “percent point function”. The 90th percentile or “90 percent point” of the curve is about 1.28:
stats.norm.ppf(0.9)
1.2815515655446004
<>:12: SyntaxWarning: invalid escape sequence '\P'
<>:12: SyntaxWarning: invalid escape sequence '\P'
/var/folders/g7/vpsqt6yn74z6qv_c_2x7jsg80000gn/T/ipykernel_53746/3708262947.py:12: SyntaxWarning: invalid escape sequence '\P'
plt.title('Gold Area: $\Phi(1.28) \simeq 90\%$');
8.2.5. Summary of Methods#
1. First, you learned to find areas under the curve based on point specified on the horizontal axis.
The main mathematical result is that for any \(z\), the area under the curve to the left of \(z\) is the proportion \(p\) given by
Numerically, stats.norm.cdf(z) evaluates to \(p\).
2. Next, you learned to find points on the horizontal axis based on specified areas under the curve.
The main mathematical result is that for any proportion \(p\), the point \(z\) that has area \(p\) to the left is given by
Numerically, stats.norm.ppf(p) evaluates to \(z\).