Variance and Standard Deviation
Contents
6.1. Variance and Standard Deviation#
Let \(X\) be a random variable and let \(\mu_X = E(X)\). The deviation from expected value, informally called the deviation from average or just deviation for short, is defined as the difference
Thus \(D\) is the amount by which \(X\) exceeds its expectation \(\mu_X\). Note that \(D\) is negative when \(X < \mu_X\).
The goal of this section is to quantify the rough size of \(D\). One natural approach is to find \(E(D)\), but that results in
No matter what the distribution of \(X\), the expected deviation from average is 0: all the positive deviations exactly cancel out all the negative ones.
The expected deviation isn’t a useful measure because it’s 0 for every \(X\). But it does help us understand what we have in mind when we say “rough size” of \(D\): we mean the value of \(D\) regardless of the sign.
6.1.1. Variance#
We could measure the rough size of \(D\) by \(E(\vert D \vert)\), but expectations of absolute values don’t have nice math properties. In particular, they don’t work well with sums. But because of Pythagoras’ Theorem, squares of distances do have good properties, especially with sums. so we will define a measure called the variance of \(X\) by
The variance of \(X\) is non-negative because \(D^2\) is a non-negative variable. Indeed, \(Var(X)\) is strictly positive except if \(X\) is just a constant.
Notice that variance is an expectation: it is the expectation of a non-linear function of \(X\). To calculate it, we can apply our familiar method of finding expectations of non-linear functions.
6.1.2. Standard Deviation#
Calculating variance takes care of the problem of positive and negative deviations canceling out. But it introduces a different problem, which is that variance is the expected squared deviation and thus has different units from the original variable \(X\). For example, if \(X\) is a weight in pounds then \(Var(X)\) is in squared pounds, and squared pounds aren’t easy to undertand.
To fix this problem we take the square root of the variance. The resulting quantity has the same units as \(X\) and is called the standard deviation or SD of \(X\).
The standard deviation will be our main measure of the variability in a random variable. We will look carefully at its use and interpretation. But first, let’s write the steps to calculate it.
Remember that the point of the SD is to measure the rough size of deviations around the expectation of \(X\). So start by calculating the expectation.
Find \(\mu_X\).
Find the deviation \(D = X - \mu_X\).
Square the deviation to get rid of the signs: \(D^2 = (X - \mu_X)^2\).
Find the mean squared deviation, also known as the variance: \(Var(X) = E((X - \mu_X)^2)\).
Take the square root of the variance to get the standard deviation: \(SD(X) = \sqrt{Var(X)}\)
If you go backwards along these steps you will see why the SD is called the root mean square of deviations from average.
6.1.3. Example#
Let \(X\) have the distribution given below.
\(~~~~~~~~~~ x\) |
\(3\) |
\(4\) |
\(5\) |
|---|---|---|---|
\(P(X = x)\) |
\(0.35\) |
\(0.5\) |
\(0.15\) |
Then
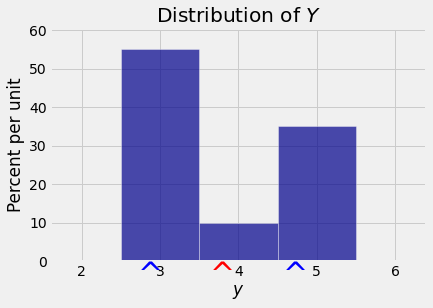
and is marked by a red arrow on the horizontal axis of the probability histogram below.
The table below shows the distribution of \(X\) along with the squared deviations:
variance_table
| x | (x - E(X))**2 | P(X = x) |
|---|---|---|
| 3 | 0.64 | 0.35 |
| 4 | 0.04 | 0.5 |
| 5 | 1.44 | 0.15 |
We now have
var_X = sum(variance_table.column(1) * variance_table.column(2))
var_X
0.45999999999999996
The standard deviation can now be calculated as
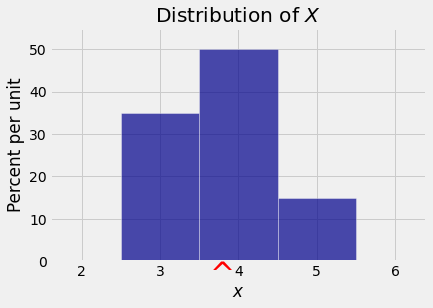
The points \(E(X) \pm SD(X)\) are \(3.8 - 0.68 = 3.12\) and \(3.8 + 0.68 = 4.48\). These are the blue arrows in the figure below, shown to indicate the sense in which the SD measures the “rough size” of the deviations. We will have much more to say about interpretation in later sections.
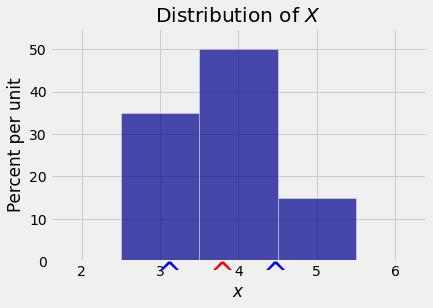
6.1.4. Example 2: Larger Spread#
The random variable \(Y\) with the distribution given below has the same expectation as \(X\) above. But its distribution looks quite different from that of \(X\).
\(~~~~~~~~~~ y\) |
\(3\) |
\(4\) |
\(5\) |
|---|---|---|---|
\(P(Y = y)\) |
\(0.55\) |
\(0.1\) |
\(0.35\) |
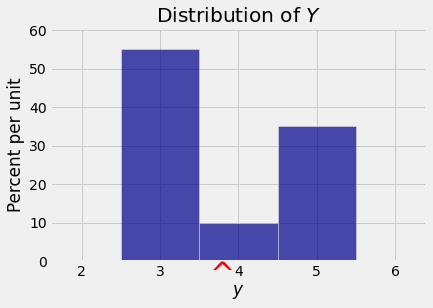
The probabilities in the distribution of \(Y\) are concentrated on the two outer values (3 and 5) whereas in the distribution of \(X\) the most likely value is 4. Because both distributions have the same mean of 3.8, the deviations of \(Y\) are more likely to be large than those of \(X\). So \(Y\) has the greater \(SD\).
You can check this numerically:
variance_table_Y
| y | (y - E(Y))**2 | P(Y = y) |
|---|---|---|
| 3 | 0.64 | 0.55 |
| 4 | 0.04 | 0.1 |
| 5 | 1.44 | 0.35 |
var_Y = sum(variance_table_Y.column(1) * variance_table_Y.column(2))
sd_Y = var_Y ** 0.5
sd_Y
0.9273618495495703
The figure below shows the probability histogram of \(Y\) along with the three points \(E(Y)\) and \(E(Y) \pm SD(Y)\). Compare this with the corresponding figure for \(X\) above. You will see that the two expectations are the same but \(Y\) has the bigger SD.